Machine learning (ML) helps Ente derive meaning out of your photos.
In this document we describe how Ente's machine learning works under the hood.
Motivation
A big part of what makes Ente Photos great are the features to help you rediscover your memories. A lot of these features are based on Machine Learning models analyzing your photos.
Since Ente is fully end-to-end encrypted (E2EE), we could not take the common approach of running these models in the cloud, simply because we do not have access to your photos. Instead, to maintain our promise of maximum privacy and security to the user, we were forced to take a more innovative approach.
This approach entails running the ML models on the only place where we actually have access to the data: locally on the user's device. Fittingly, this approach is referred to as on-device or local ML. But despite having a definition, on-device ML is still new.
The industry standard approach has been cloud-based for several reasons:
- Infinite compute
- Full control over the runtime environment
- Easy access to (python-based) ML libraries
Following that logic, some of the biggest challenges we faced with on-device ML are:
- Limited compute
- Having to work on many different platforms
- Limited access to ML libraries
Despite these challenges, we still had very good reasons to choose this path:
- Guaranteed privacy, as no data has to leave the device
- Lower cost, as we don't have to maintain or buy ML compute
- Lower latency, as search is done without waiting for any network requests
The first reason was the deciding factor, but the point is that on-device ML, if done well, is by no means inferior to the common approach of cloud-based ML. Rather, the choice between these two will depend per use-case on the constraints and requirements. As consumer devices become more powerful and techniques for efficient models continue to improve, this balance is shifting more in favor of our approach.
Implementation details
Fundamentals
Some key definitions to understand.
The process of analyzing images is called indexing. We refer to the results as indexes.
A cluster is a grouping of similar items. Clustering is the process of creating a cluster by grouping similar items together.
A person entity contains information about a detected person. It consists of a group of clusters of faces belonging to the person, plus optional information the user assigns to it (e.g. name, date of birth).
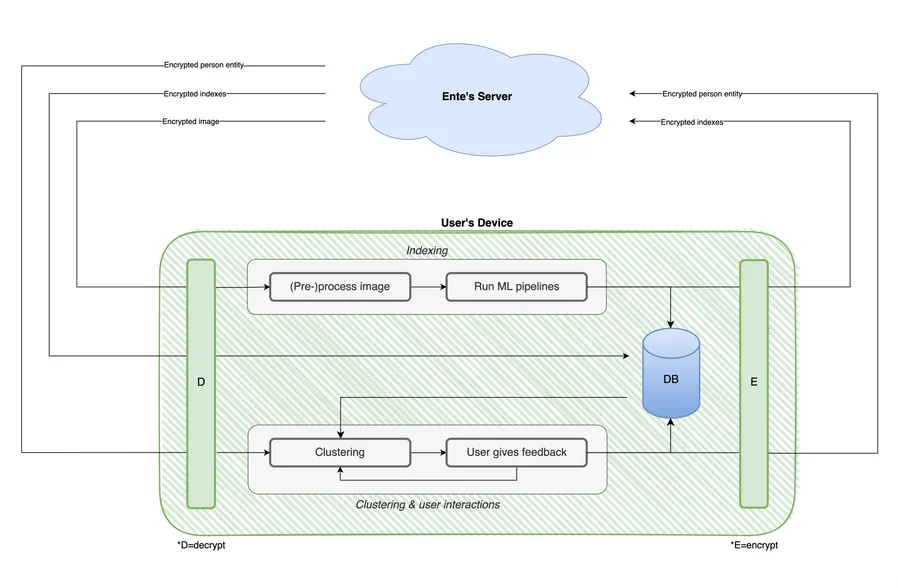
Key flows
We have a central service running in each client that orchestrates the ML setup. The most important flows on the client are the indexing, clustering and the user interactions.
Indexing flow:
- Each client pulls any existing indexes from Ente’s server before indexing locally.
- Indexing locally starts by fetching the images. If an image is not present on the device it will be downloaded.
- After fetching and decrypting the image it is decoded and processed for analysis. Image (pre-)processing is done using custom code written for each platform.
- The ML models are stored in ONNX format, and inference is done using ONNX Runtime.
- All indexes are stored locally. They also get encrypted and stored on the server.
- Because analysis is done locally and no image or index leaves the device un-encrypted, privacy is guaranteed.
Clustering & user feedback:
- Each client pulls any existing person entities from Ente’s server, which includes groups of clustered faces.
- Once indexing is complete, the resulting (face) indexes get clustered. Existing (synced) clusters remain intact.
- The user can give feedback in the app, altering the existing clusters.
- All cluster information is stored locally. Clusters named or altered by the user are encrypted as a person entity and stored on the server.
- Because clustering is done locally and person entities are encrypted before leaving the device, privacy is guaranteed.
Semantic search
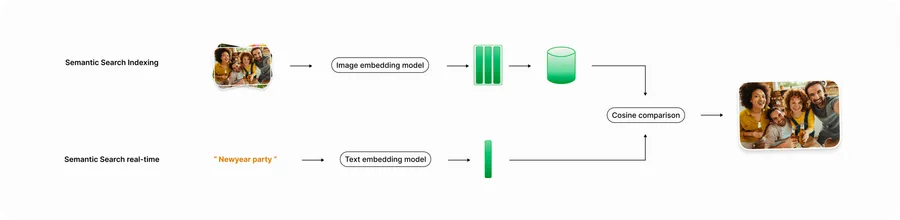
Semantic search, branded as Magic Search, allows the user to search for images using any natural language prompt (e.g. "dinner party with parents"). It is based on Apple's MobileCLIP model (v1), which itself is an iteration on OpenAI's original CLIP (Contrastive Language-Image Pre-training). The model consists of two encoders, one for images and one for text, both of which produce embeddings in a similar embedding space (meaning they can be directly compared). An embedding can be seen as a mathematical representation of the information content in the original medium. A common way to compare embeddings is by calculating the cosine similarity.
The essence of the semantic search pipeline is very simple:
- Each image is indexed by locally running the image encoder on it. The resulting embeddings are stored in a local database.
- Once the user searches for something, we take their search query and run it through the text encoder.
- Then we take all the image embeddings from the database and compare them with the text embedding. This comparison is done by calculating the cosine similarity between each pair.
- All images with a similarity above a certain threshold are shown as search results to the user.
Face recognition

Face recognition allows the user to search for images with specific people in them. Multiple different models and algorithms are used to make it work.
Face detection
First we run face detection on the full image to find out if any people are present. The model we use is YOLO5Face, which is the leading architecture for object detection repurposed for faces. We're using the small variant to balance model size and performance. The model produces a list of possible faces, which are filtered using Non-Max Suppression. The resulting faces, or absence of them, are stored in the local database. If no faces are found the pipeline stops here for the given image.
Face alignment
If faces are detected, the next step is to align them using geometric transformations. The idea here is to neutralize as much noise as possible regarding the positioning of the face, such that all focus is on the actual characteristics of the face. The alterations are done through our own custom implementation of similarity transformations.
Face embedding & metrics
The aligned faces are fed into the MobileFaceNet model, which results in a unique embedding for each face. The model is trained in such a way that similar faces will result in similar embeddings.
We also record certain metrics on each face, such as the blurriness of the face and the positioning.
Clustering
Once all images are analyzed and all faces indexed, the clustering process is triggered. The overall idea is that when clustering all face embeddings in groups, each group will correspond to a single person.
For the clustering we use our own custom algorithm, which we internally refer to as linear incremental clustering. Linear refers to the fact that clustering happens in a chronological order, while incremental implies that new clustering rounds on new information yield the same result as one clustering round on all data together. The first helps us balance speed and accuracy, while the latter is crucial to incorporate user feedback. Our clustering also takes the recorded face metrics into account to prevent wrong cluster groups.
Feedback
Though the above approach works well, the stochastic nature of ML means that no approach will be without mistakes. The current system is designed such that it can be easily corrected by the user. For instance, we’ve made it easy for the user to merge clusters, break them apart, or remove individual photos from them.
Syncing results
The derived information is synced E2EE across platforms. Syncing ML data is a unique approach we’ve taken to streamline the experience for our users. It takes away common friction points of on-device ML.
For instance, when logging into a new device, it will pull the information from the Ente server instead of having to derive everything again. It also allows indexing to happen on more powerful devices, which can then be used by weaker devices. Most importantly, it means any feedback by the user only has to be given once, yet will be respected on any (future) device.
The synced information consists of two parts:
- Indexes. All derived information from an image. This includes both the image embedding and any face embeddings. The information is compressed lossless and encrypted using the file key before being sent to our object storage.
- Person entities. All clusters of faces that are found to belong to a certain person. It also includes optional information provided by the user, as well as any feedback given by them. The information is compressed, encrypted and then stored in our central DB.
Cross platform
Both the ML indexing and the resulting features work on every platform. A lot of effort has been put in to ensure results are exactly the same across platforms. We’ve extensively tested every stage of our pipeline across all platforms, to make sure every pair of embeddings is comparable irrespective of their origin.
The only difference between platforms is the time it takes to index. For this reason, we recommend that users run the initial indexing of their library on the desktop app and let results sync automatically to the mobile app. After that, the mobile app should be enough to keep up with any new photos taken.
New users importing their library in the desktop app will automatically benefit from indexing there, provided they enable ML from the start.
Safe-guards
Running models locally can be taxing on the device, especially for older generation devices. To prevent causing any kind of degradation, we put in place multiple safeguards. Key considerations are temperature of the device, battery levels, and how active the user is using the phone.
We run indexing when the device has a stable and unmetered connection. Depending on how many files are only in the cloud, downloading those files for indexing could take up quite a bit of bandwidth, and we don't want users with small data packages to have any bad surprises.
Challenges to on-device ML
There are still many implementation details we have left out, for the sake of clarity. Some of the more interesting details we haven't discussed:
- Choice of model architecture; Most of our models were chosen and made to work well on mobile devices.
- Quantization; We were able to shrink the size of our semantic search text encoder by ~70% without a noticeable decline in quality.
- ML Lite; To accommodate even the oldest and most compute-constrained devices, we've introduced a lite version that doesn't index by itself but can still use existing (synced) results.
- We've spent an ungodly amount of time getting the image processing exactly right; For example, we've written from-scratch implementations for advanced interpolation methods, such as Lanczos and Cubic interpolation. Image processing methods can make or break any computer vision experience, as artifacts such as aliasing can have significant negative effects on the model output. “Garbage in = garbage out”, and we want the best output.
- Finding the right clustering algorithm is a hard technical challenge. The biggest problem is that there is no ground truth to evaluate against. What works wonders for one photo library can be terrible for another. And there is no user data to test against. We’ve gone through countless iterations of our clustering, and will continue perfecting it in the future.
- We've become very comfortable rewriting existing data science (Python) packages for our specific platforms, be it in Dart, Javascript, Kotlin, Swift or Rust.
Gratitude
We want to take a moment to acknowledge the work of others that made our approach possible. Being an open-source company ourselves, we are grateful for all the work others have done to lay the groundwork.
There are two groups to explicitly mention.
The first is the work of the good people at ONNX and ONNX Runtime (ORT). ONNX is an open format for ML models, focused on interoperability and maintained by the Linux Foundation. ORT is an inference engine for ONNX models that makes it easier to run models across many different devices and platforms.
The journey to arrive at ONNX and ORT was a long one. We started out using Google's TFlite (now LiteRT), have dabbled with Pytorch Mobile (now ExecuTorch), and even used GGML in production for a while. While all of these ML frameworks come with their own perks and quirks, we have grown to love ORT for its reliability across many devices and its interoperability to accommodate all kinds of different models. We believe it's the most mature framework for on-device ML.
Secondly, we're grateful for the open-source ML community in general. Having no access to user data means we are somewhat dependent on public data and pre-trained models. Luckily, that community seems to be thriving more than ever.
Looking forward
We're only getting started with ML. We have spent the past two years building up the needed expertise to pull off on-device ML effectively. Now we start to pick the fruits from all that labor. As face recognition and semantic search mature, new cool features will be built on top of it. Moreover, we'll explore new use cases based on new models.
We feel strongly that on-device ML is the best way for us to provide a great experience to our users in a completely private way. That said, we are not dogmatic about it. We're always out looking for the best way to provide value, and that might mean trying out new techniques in the future, such as Full Homomorphic Encryption (FHE) or our own open-source Private Cloud Compute (PCC). Not to replace our current tools, but to complement them, together delivering an optimal experience for our users.